the prompts-method can be structured this way:
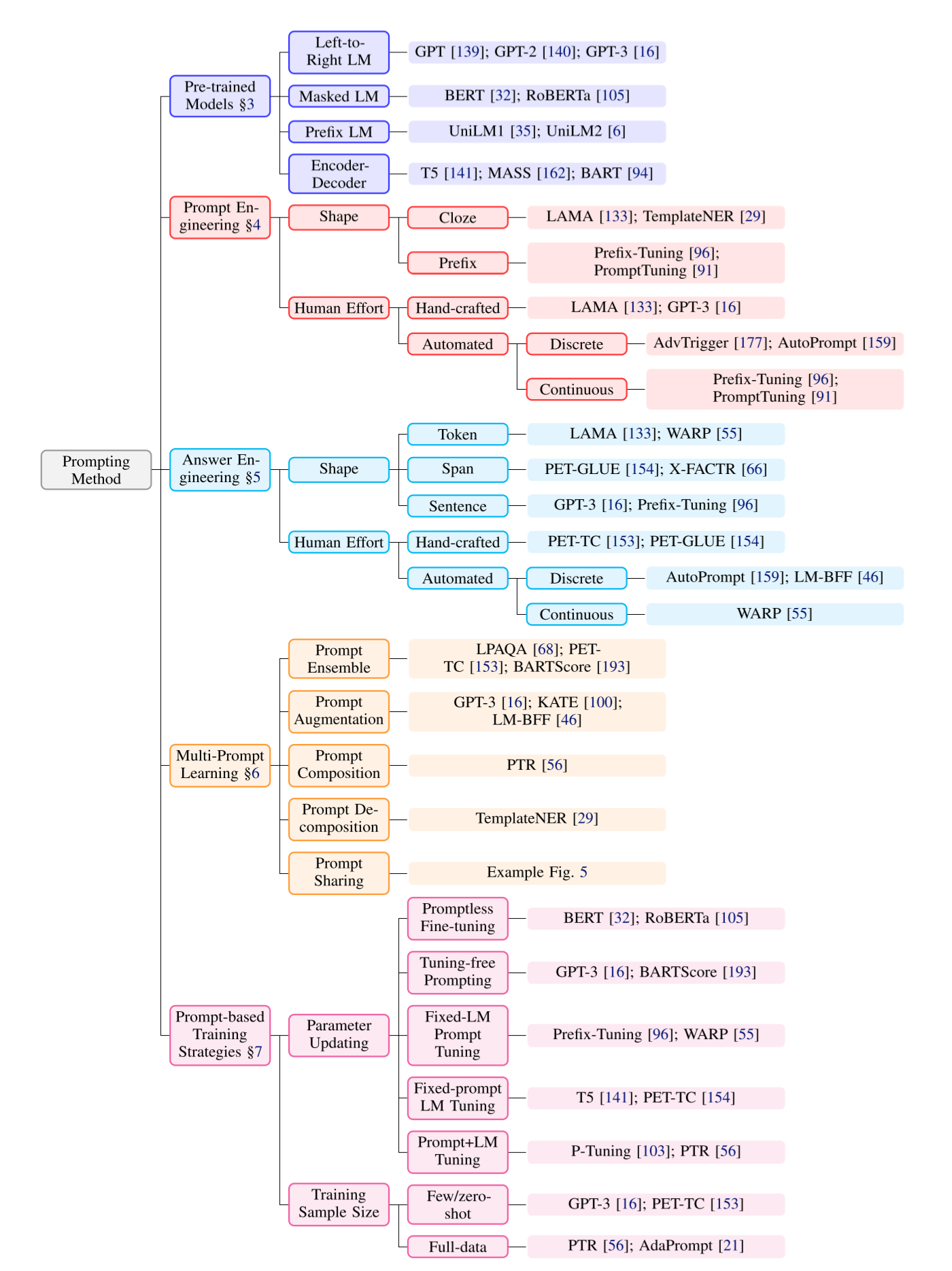
Pre-trained Models Selection
two main training objectives
- Autoregressive fashion LM
- denoising objectives –> loss over only noised parts or all parts
different objectives suit for different downstream tasks.
four paradigms of PTMs
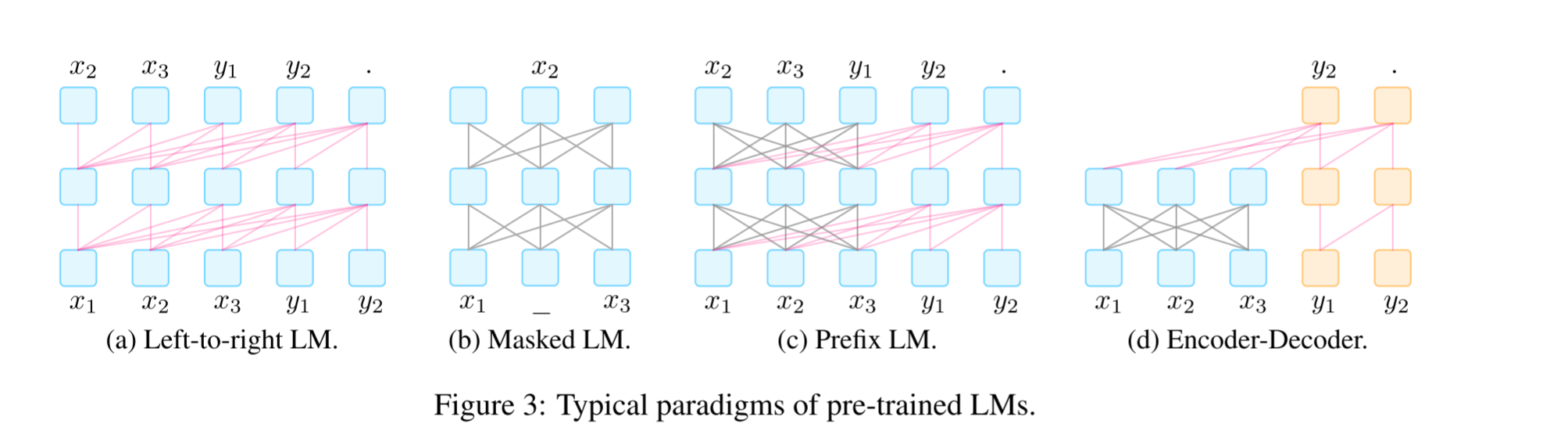
in prefix LM, encoder and decoder share params and encoder often adpots coruptions with according objective.
Prompt Engineering
Prompt shape
- cloze prompts
- prefix prompts
Manual Template Engineering
- LAMA dataset provides cloze templates
- Brown et create prefix prompts
Automated Template Learning
Discrete Prompts(hard prompts)
Some methods are as below:
- Prompt mining: scrape a large text corpus(Wiki) for strings containing [x] and [y], find middle words or dependency paths as prompts
- Prompt Paraphrasing: paraphrase seed prompts into a set
- Gradient-based Search: search over actual tokens
- Prompt Generation: use standard generation model
- Prompt Scoring: use unidirectional LM to score prompts
Continuous Prompts(soft prompts)
motivation: it’s not necessary to limit the prompt to human-interpretable language
some methods are as below:
- Prefix Tuning: tune task-specific vectors
- Tuning initialized with discrete prompts: initialize with discrete prompts and then finue-tune the embeddings.
- hard-soft prompt hybrid tuning: insert tunable embeddings into a hard prompt template
Answer Engineering
Answer Shape
- tokens
- span
- sentence
Design the Map From Answer Space to Output Space
Manual Design
- Unconstrained Spaces: identity map
- Constrained Spaces: map between answer and the underlying class
Discrete Answer Search
- answer paraphrasing: expand answer space to broaden its coverage
- label decomposition: decompose label into constituent words
Continuous Answer Search
assign a virtual token for each class label
Multi-Prompt Learning
use multi-prompt can improve model’s performance further
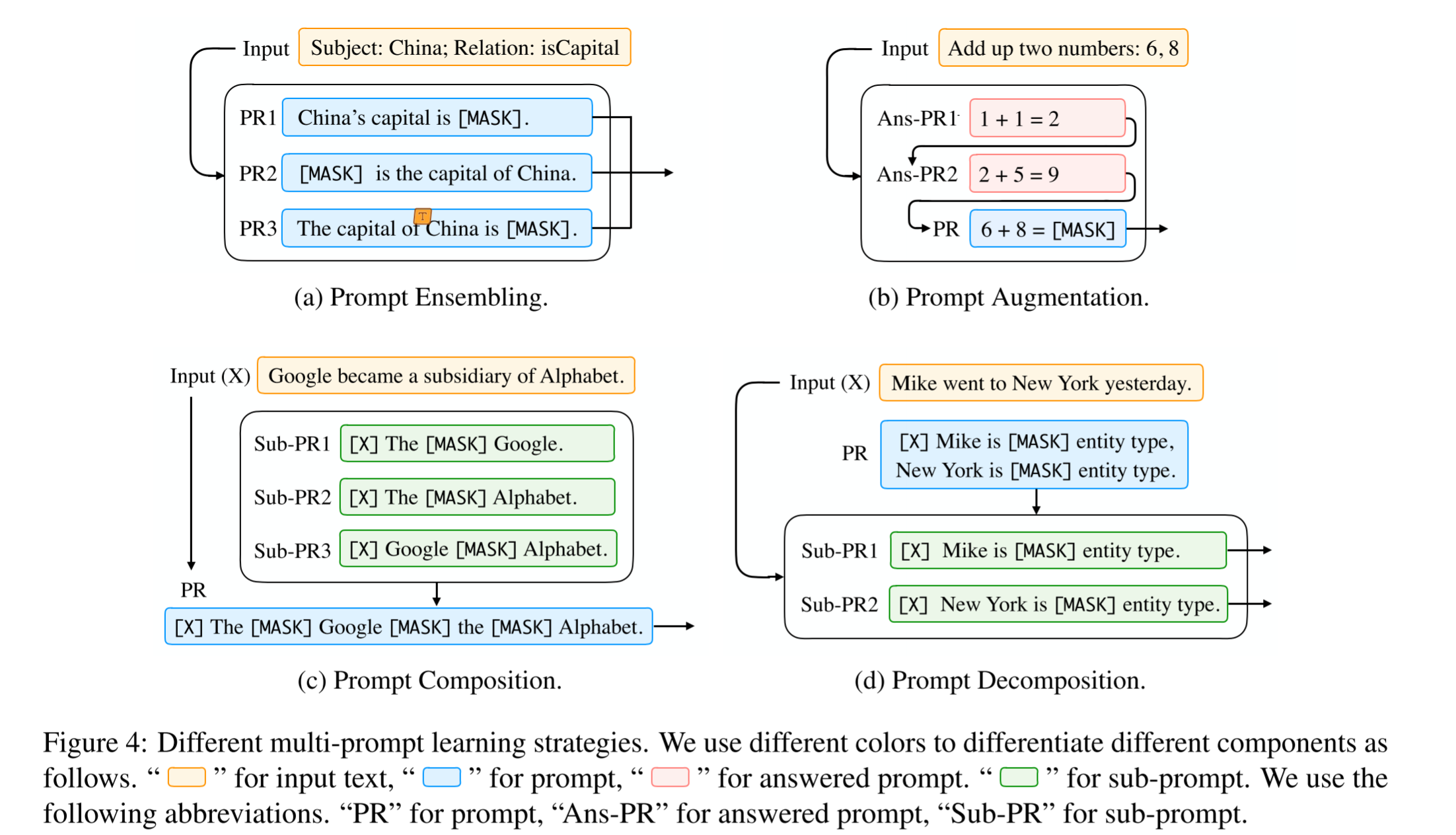
Prompt Ensembling
- Uniform average: take the average of probabilities from different prompts
- Weighted average: the weights are pre-specified or optimized over training-set
- Majority voting: for classification tasks
- Knowledge Distillation
- Prompt ensembling for text generation
Prompt Augmentation
also called demo learning, which is prefixing a few examples to the prompt. These few-shot demos take advantage of the ability of LM to learn repetitive patterns
Sample Selection
different samples can result in quite different performance(ranging from SOTA to near random guess)
- Sentence Embeddings to sample examples close to the input
- provide positive samples and negative samples
Sample Ordering
sample order is quite important also
- entropy-based methods
- search and learn a separator token
- retrieval-based methods(add more context)
Prompt Composition
use sub-prompts to compose a prompt
Prompt Decomposition
break down the holistic prompt into sub-prompts
Training Strategies for Prompting Methods
Training Settings
- zero-shot
- few-shot
- full-data
Update methods
there are five tuning strategies refered
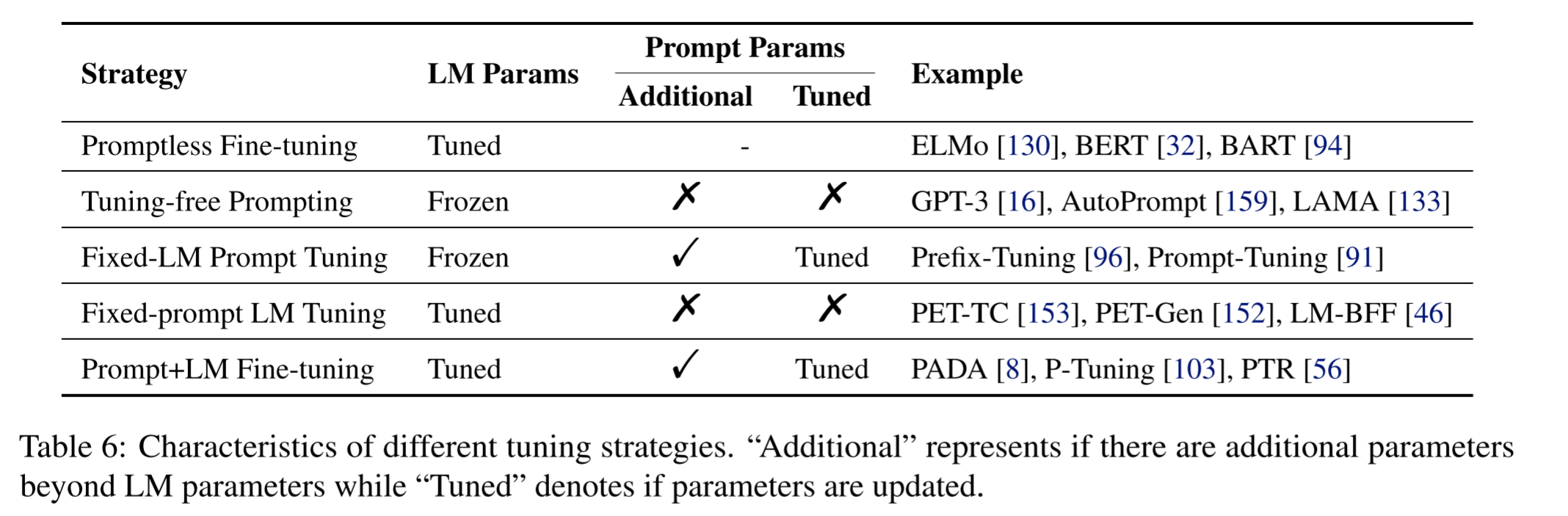
- Promptless fine-tuning
Ad: no need for prompt design
Disad: overfit and catastropic forget
- tuning-free prompting
also called in-context learning, typical examples of tuning-free prompting include LAMA and GPT-3
Ad: efficiency and no catastrophic forgetting
Disad: heavy engineering is needed, test-time can be long
- fixed-LM Prompt Tuning
typical examples are prefix-tuning and WARP
Ad: retain knowledge in LMs, suitable for few-shot settings
Disad: prompts are usually no human-interpretable
- fixed-promp LM Tuning
- Prompt+LM Tuning
Ad: most expressive method, can provide bootstrapping at the start of model training
Disad: overfit small datasets
Resources
Dataset
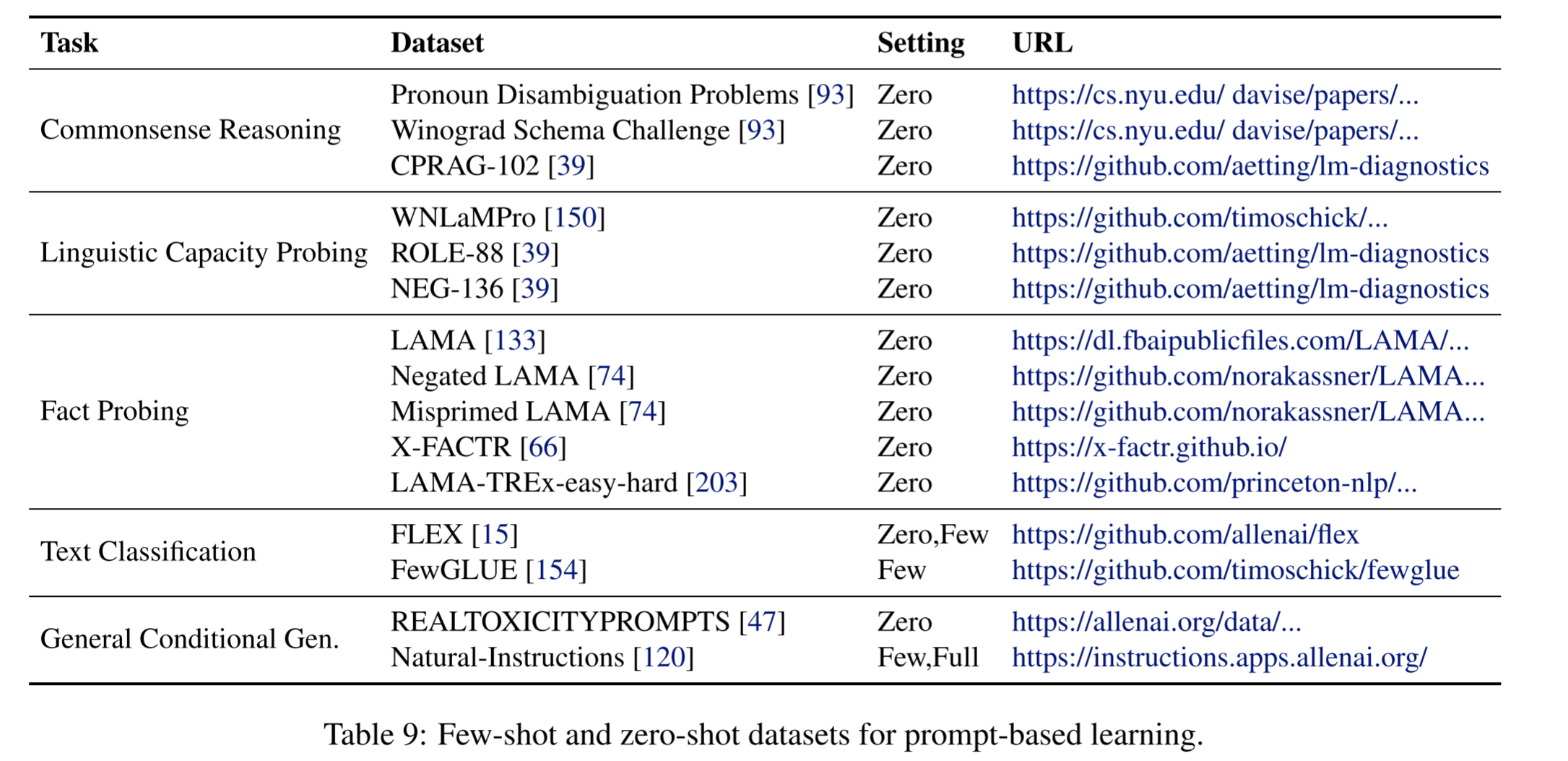
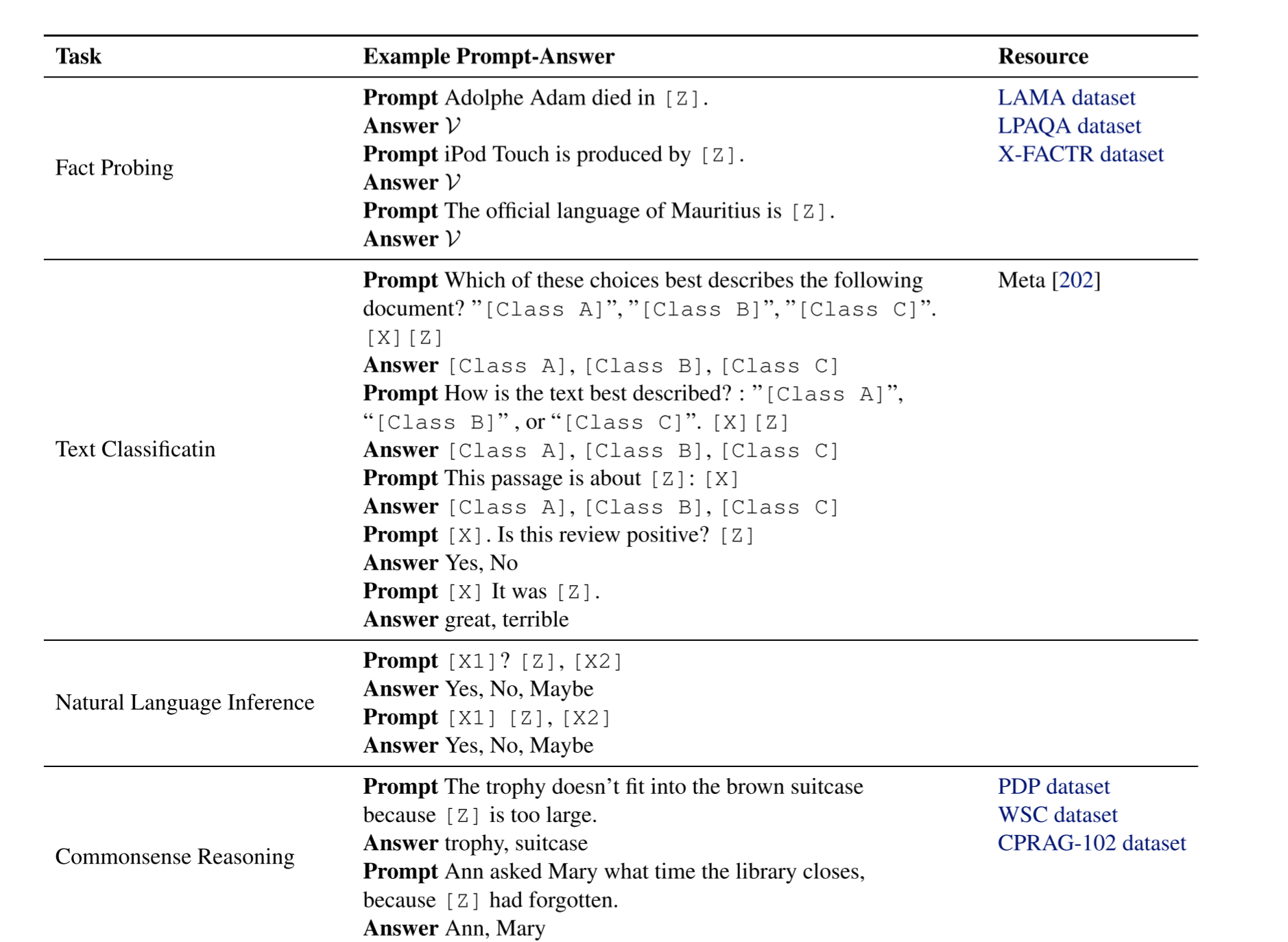
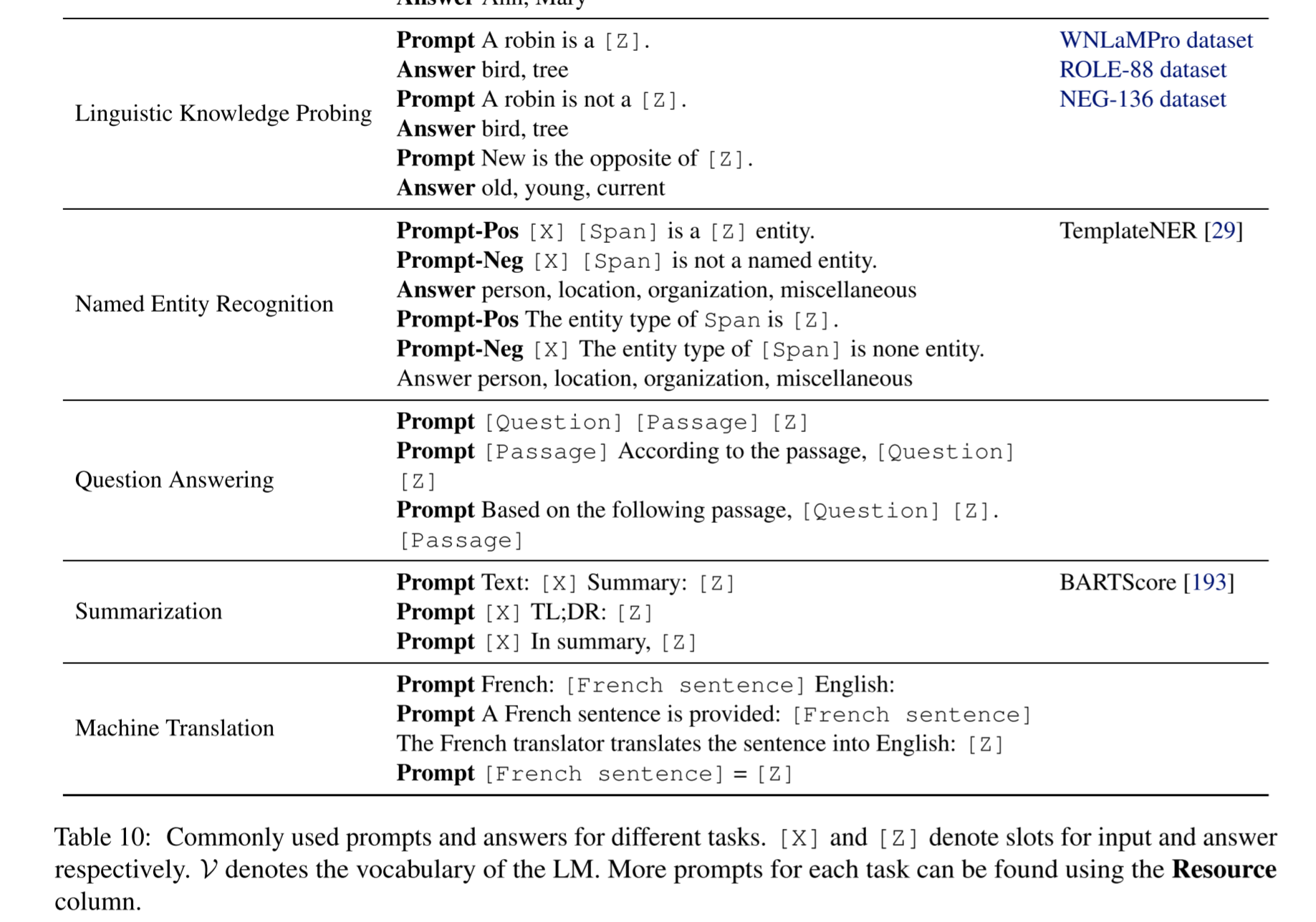
Prompts
existing commonly-used prompts designed manually
Prompt-relevant Topics
Ensemble Learning
Prompt ensembling becomes another way to generate multiple results to be combined withou traning the model multiple times
Few-shot Learning
Prompt Augmentation can be viewed as a way to few-shot learning, which elicit knowledge from LMs explicitly
It’s also related to large-context learning
Query Reformulation
elicit more relevant texts by expanding query with related query terms
LM can be viewed as a kind of query, but the knowledge bases are a black-box
Conclude
The timeline of researchs on Prompt-based learning can be found here.
This blog is a summary on Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing, a very beginner-friendly material for the start of prompts-bsaed learning.
Author: Type-C, yanpengt06@gmail.com