情感分析综述:方法、应用与未来
情感分析的尺度
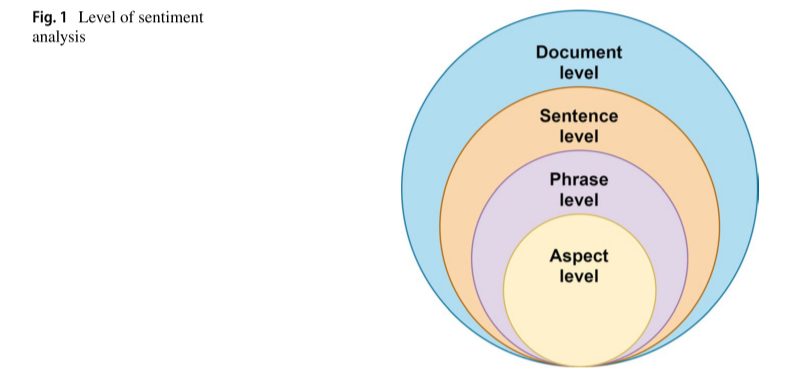
情感分析(Sentiment Analysis, SA),在NLP领域特指文本情感分析,即分析文本所蕴含说话人想要表达的情感。尺度由小至大依次是方面(Aspect,翻译可能不当,下文仍采用英文)级、短语级、句子级以及文档级的情感分析,以下分类阐述。
文档级SA
为整篇文档分配单一情感极性,在该尺度上进行分析通常较少。跨领域、跨语言是在该尺度上开展的重要任务,特定领域的SA已经取得了较高的准确率,但是特征向量也会因为领域之间的差异性而难以迁移。
句子级SA
可聚合从而决定文档的情感极性。在先前工作中,句子级SA被用来寻找主观句;在较为复杂的任务,例如分析有歧义的语句以及条件句,语句级别的SA也是必不可少的。
短语级SA
每一个短语可能包含多个aspect或者一个aspect,从而蕴含着相应的情感极性。一个比较有趣的是用来表达情感的短语,具有一定的群体特征(性别、年龄、种族),也十分值得挖掘。
方面(Aspect)级SA
类似地,Aspect的情感极性可以聚集,从而决定一个句子的情感极性。举个例子:这个相机价格有点高,但是拍出来的照片质量很好!这个主观句包含一个对象的两个方面(Aspect),一个描述方面是相机的价格,贬义;另一个是相机的拍照质量,褒义,从一些介词副词可以分析出大体上语句仍是褒义的。
情感分析的Workflow
数据收集与特征选择
- 数据收集
互联网各类应用兴起后,数据可以说是海量的,来源广泛、良莠不齐。主要来源包括但不限于:网页,社交媒体,新闻及评论,电商网站,论坛,博客……
- 特征选择
对于分类任务,特征的选择至关重要。一些可以参考的特征:Uni-gram, Bi-gram, …由于主观语句的特殊性,还可能包含标点信息以及Emoji表情信息,俚语信息等。
- 特征抽取
与特征选择概念上边界模糊,经常抽取的特征包括不限于:词频(TF-IDF),POS(Parts of Speech, 词性)标记,否定词(否定词对于情感分析至关重要,但有时他们会在停用词表里,或者在情感词典中是中性词而不对句子极性造成影响,实则不然,要视情况处理)以及BOS(Bag of Words)特征。
词向量也是对文本特征的一个抽取,无论是静态词向量又或是动态的词向量(自ELMO起),所蕴含的特征都较为丰富,富含语义信息。
- 特征再选择
经过抽取后的特征可能是重要的、不重要的、冗余的,因此需要进一步选择(不同于2中的选择,那个更倾向于抽取)。主要方法包括基于词典与统计方法。
a) 情感词典是由WordNet数据库构造而来,其中的每一项都对应一个数值,表示情感极性(例如越高越积极)。主要缺陷就是需要大量人力标注及专家知识,且人对于情感的标注具有主观性。
b) 统计方法主要包括四类:
- 过滤方法:不采用任何机器学习技术,仅依据统计指标,排序靠前的特征则被选择,主要指标有信息增益、互信息等,计算开销小。
- Wrapper(包装?)方法:基于机器学习算法的输出,计算开销较大,可以确定最优特征子集,主要基于朴素贝叶斯、SVM等机器学习算法
- 嵌入方法:将特征选择过程包含在模型算法的执行过程之中,主要基于一些决策树算法,个人理解是通过剪枝从而完成特征选择,实现特征向量嵌入到一个低维子空间,因此叫嵌入方法?
- 混合方法:结合上述多种方法。
情感分析的主要任务及必要性
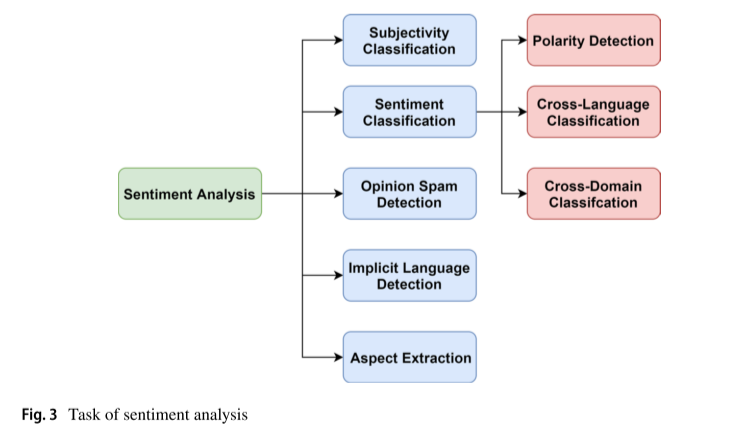
主观句识别
常被认为是SA的第一阶段任务,从文本中抽取出带有主观情感的语句。
情感分类
是情感分析的一个主要任务,包括情感极性的分类(积极,消极,中性等)以及跨语言、跨领域情感分类等子任务。词的情感具有二义性是主要困难之一,即情感也由上下文决定。”这个相机的价格好高“与”这个相机的像素好高“中的”高“具有情感的二义性。值得一提的是,情感计算(Affective Computing)与情感分析也常作为其他系统的一个子系统使用,具有重要价值。
垃圾观点检测
许多主观评论可能由机器生成,例如评论水军,这类评论被称为垃圾评论,若不剔除会对情感分析的最终结果有较大干扰。机器学习算法是主流方法,常用方法还有:引入商品打分信息,评论用户的IP、打分偏好等信息,以及一些常识知识等其他信息。
隐式情感分析
反讽、幽默常被称作隐式情感,这些模糊、隐晦的表达使得情感分析任务变得更加困难,是情感分析的一个具有挑战性的子任务。经典的方法有引入emoji,标点符号等信息,辅助判断。一个讽刺的例句:
“Brilliant, I am fired!”
Brilliant作为积极词汇在讽刺语句中起到了加强消极极性的作用。
Aspect抽取
方面级的SA主要由aspect抽取,极性分类,极性聚集三个步骤组成。
aspect抽取的主要方法包括采用预定义集合,基于频率,基于语法,监督和无监督机器学习方法。以上方法各有优劣且互补。
必要性
情感分析因其应用广泛而具有充分的研究必要性,也是近年来的一个热门研究领域。其常见的应用有:
经济
商品评论分析,客户满意度分析从而促进商品不断迭代
对用户的喜好建模,也可以被推荐系统所用,构建更加智能的推荐系统
产品公关,通过分析关于品牌的讨论、舆情,制定相应的策略。
股价预测:类似舆情分析,关于股市的舆情,进而预测股价、比特币等价格。
涉及的技术包括但不限于细粒度情感分析,aspect-level情感分析,评论摘要的生成。
政治:对于热点事件,分析国民情绪(舆情分析)对于社会治理有重要作用。
医疗健康
- 当下,精神类问题、疾病所占的比重日益增大, 从情感、心理学层面进行预防及治疗可以有效解决精神健康问题。
- 普通医疗方面情感分析可用于监测病人的状况,确定病人的需求。
情感分析的方法概述
基于词典的方法
如前文所述,情感词典是一些token的集合,每一个token被分配了一个数值以表示情感极性。基于词典方法的优势主要有无需训练数据,被视为是一种无监督方法;缺点也因此而产生,词典的构造需要专家知识,耗费人力物力且具有高度的领域相关性,在领域之间的迁移性极差。主要有两种基于词典的方法:基于语料库的方法与基于字典方法,下面分别阐述。
a) 基于语料库的方法
该方法考虑语义及语法模式来确定一个句子的极性。该方法首先预定义一个情感词术语集合及其极性,然后在巨大语料库中根据语法pattern,来发现情感词及其对应极性。前人的一些工作包括:利用了AND这类关联词所在两侧情感极性往往相同,即”情感一致性“等。
基于语料库的方法有两种类型:统计方法和语义方法
统计方法
种子观点词与上文所述的共现Pattern可以通过统计方法获得。主要思想是: 经常出现在积极语句中的词语本身有更大的可能是积极的。主要方法是:若某些token经常在相同的语境中出现,他们往往具有相同的极性。一个比较有趣的是,基于共现的统计方法可以用来检测虚假评论:评论的写作风格正常情况下应该是随机的,而不应该具有某种pattern,若不然,则很大可能是同一个用户批量撰写的虚假评论。
另一个统计方法是LSA,即隐语义分析。
- 语义方法
通过计算词语之间的相似性完成情感极性的判定:同义词往往有相同极性,反之。
b) 基于字典的方法
基于字典的方法包含一系列人工收集的预定义观点词集合。主要假设仍是同义词往往具有相同的情感极性,依据此不断扩充这个Opinion Word 的集合。
基于词典的两种方法优劣如下图所示:

机器学习方法
本质上也是做特征提取和表示学习,用深度学习的方法做表示学习,具有高准确率、拟合能力强等特点。采用ML方法可以更好地理解上下文信息,完成反讽识别等较为复杂的情感分类任务。下面是一些常用的机器学习方法在SA领域的应用。
- Naive Bayes
概率分类器,基于贝叶斯理论,建立在特征提取之后。
- SVM
有监督学习分类器,习得参数只取决于支持向量,十分高效且鲁棒。
- Logistic Regression(LR)
运用在分类任务上的概率回归模型,是一种线性分类器。
- 决策树与随机森林
通过样本基于一些指标(互信息等)学习最优决策属性,也十分高效。
- 最大熵模型
条件指数分类器,是一种基于特征函数学习权重的分类器,关键在特征函数的构造,往往也需要特征工程。
- KNN
基于投票的分类器,在SA领域运用得不广泛,若经过恰当的训练,能取得不错的效果。
- 半监督学习
训练集包含标注数据与部分未标注数据,在现实中较多场景符合此情景。、
注:上述方法大部分均建立在 特征提取之后,好的特征对分类好坏至关重要,至于如何提取特征,如前所述或是用深度学习方法做表示学习都可能有不错的效果。
混合方法
顾名思义,结合机器学习与词典的方法,取长补短,往往有不错的效果。
深度学习方法
神经网络大火之后,用深度学习做表示学习在效率、效果上都远高于传统机器学习及基于词典的方法,各类网络架构在SA得到广泛应用,在各大任务上均有所突破,不详述,具体的一些应用如下表所示:
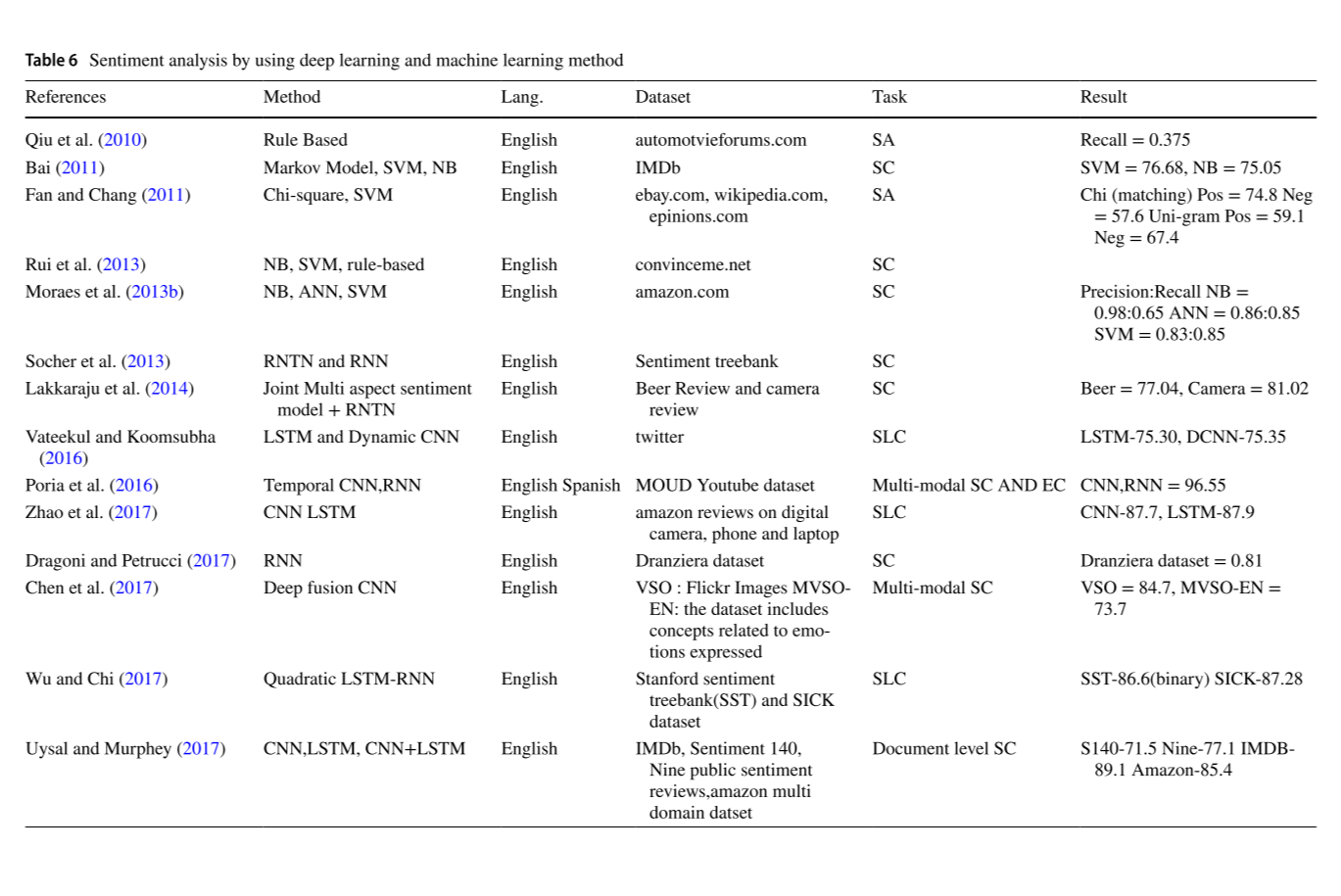
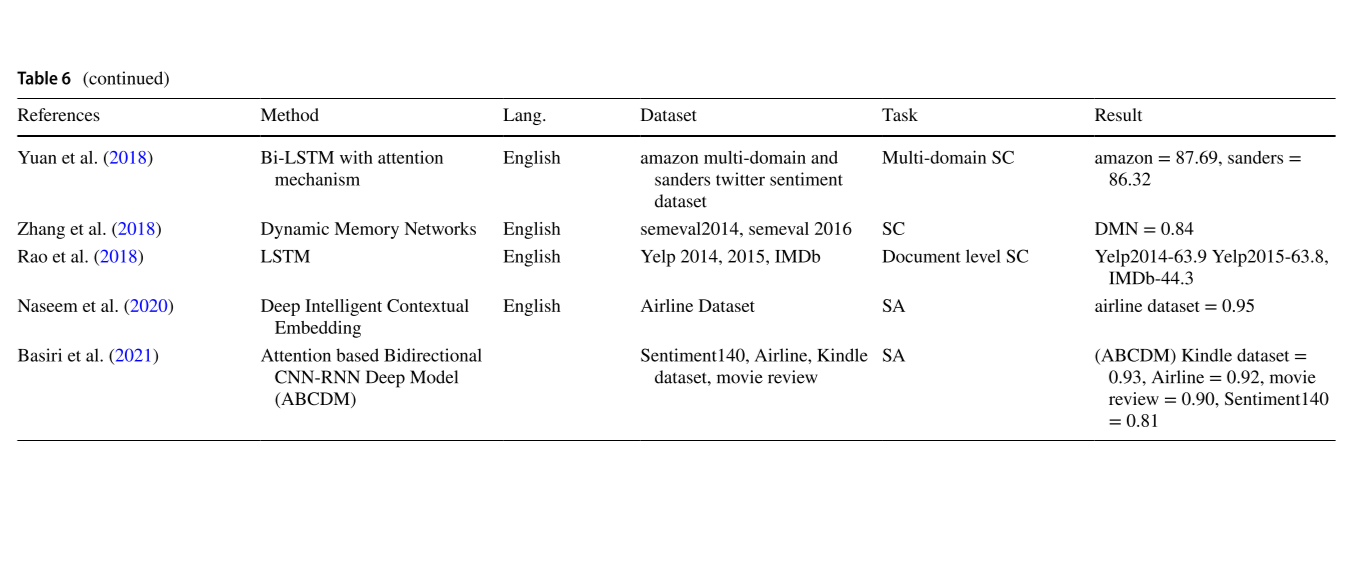
其他方法
a) Aspect-based Sentiment Analysis(ABSA)
ABSA是一个有价值且近年较热门的一个情感分析方向。包括三个阶段:aspect检测,极性分类以及极性聚集。该方法被广泛运用于文本评论分析中,举个例子:
The food was awesome, but service was slow.
Aspects可以有显式以及隐式两种定义方式,比如预先定义Implicit Aspect A= { taste, food }。那么上述例句的两个aspect分别是taste与service,情感极性分别为:积极,消极。那么简单地情感极性聚集后,该评论为中性评论,当然也可以有其他情感metric的定义方式。
b) 迁移学习
预训练-精调已成为NLP任务的新范式,迁移学习也能很好地应用在SA领域,经过精调后即可将SA任务从一个特定领域迁移到另一个领域,完成Cross-field。
多模态情感分析(Multimodal Sentiment Analysis)
多模态为SA任务增加了一个level。主要模态包括:音频,图像。音调及表情可作为额外的信息辅助SA任务。MSA任务主要关注特征融合过程的设计,包括但不限于:基于注意力的模型,基于张量的模型。
评测指标
常用的指标包括但不限于:P, R, F1 value, Accuracy, Specificity, TF-IDF等
挑战与未来
文体不正式带来的计算开销大
需要处理各个语言场景下的情感分析
传统方法难以分析隐式情感
标注成本高,需要低资源场景下的方法
大模型计算开销高
Cross-domain问题
程度副词的处理(slightly, barely, really)
混合语种语句难以处理
语言的更迭快(时空上皆有变化)
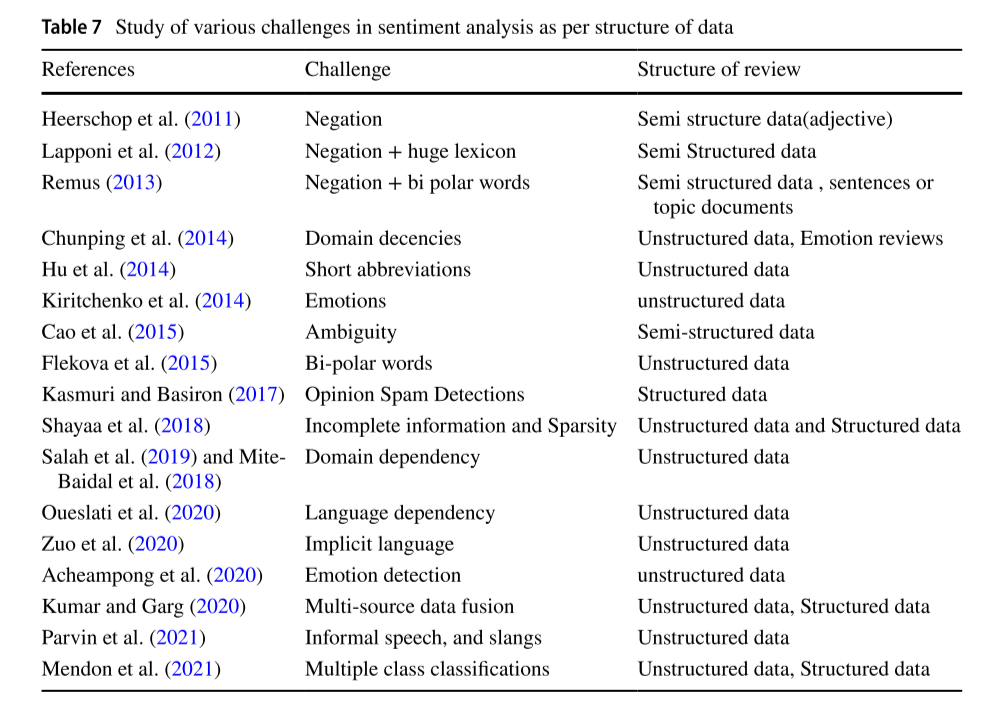
按照数据是否结构化的分类如下图所示:
小结
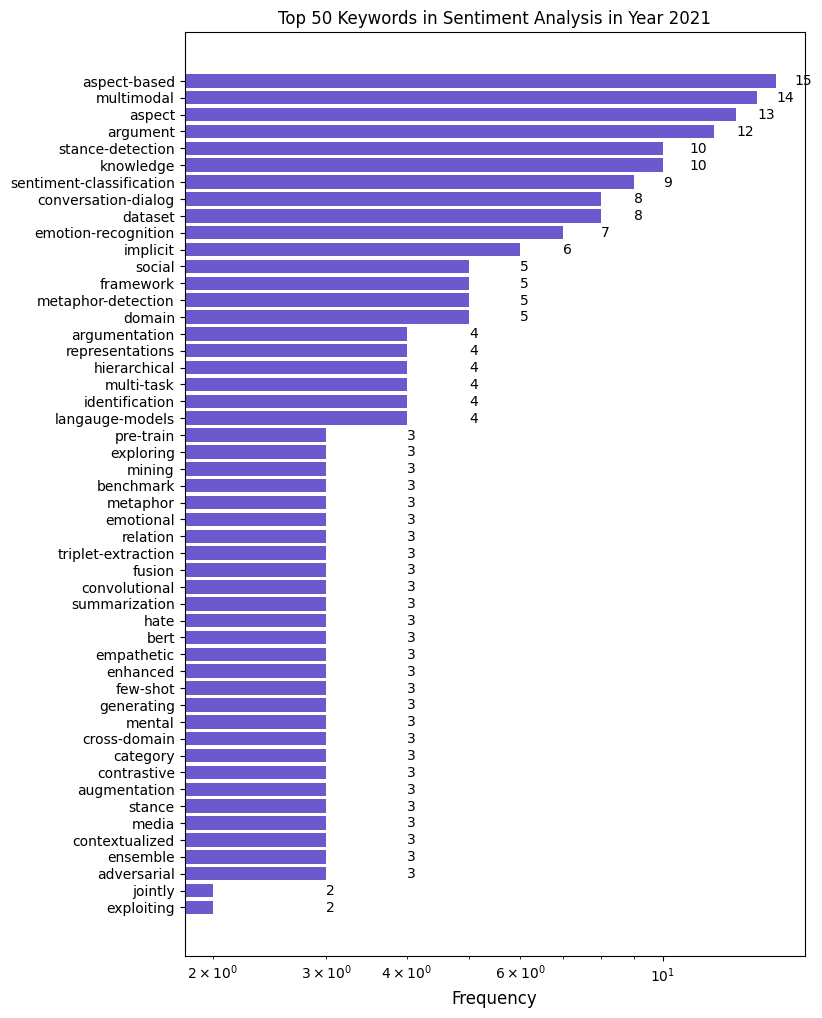
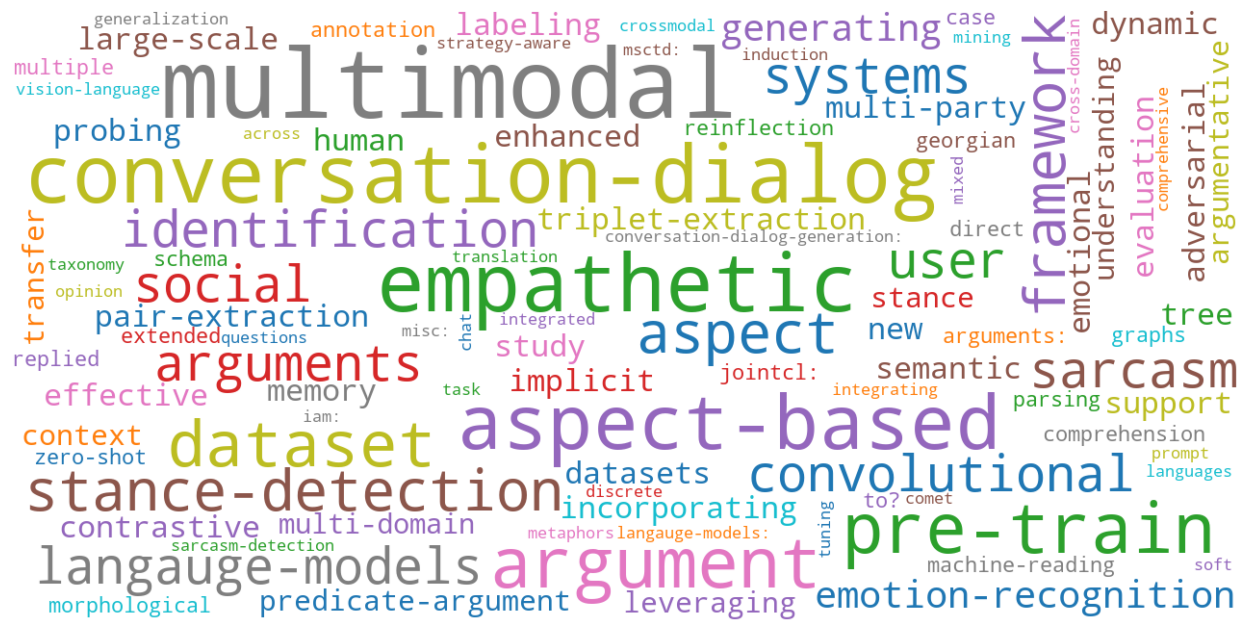
本文是对综述^[1]^的一个小结,情感分析是NLP一个较为热门的子领域:不完全统计^[2]^,近五年(2018-2022)共收录相关论文297篇,上方两张图也能阐明了近年领域研究的一些热门方向:情感对话,让人机对话更关注人的情绪,具有一定共情能力;多模态情感分析,利用各类模态信息进一步提升情感分析的准确性;反讽、隐喻等隐式情感分析一类较困难的任务;与精神健康、心理疾病检测相关的情感分析这一逐渐重视的研究方向;一些立场检测、辩论相关工作。以及一些重要的研究方法:基于预训练的迁移学习,多任务学习,少样本学习,引入外部知识等。
Reference
[1] Wankhade M, Rao A C S, Kulkarni C. A survey on sentiment analysis methods, applications, and challenges[J]. Artificial Intelligence Review, 2022: 1-50.
[2] 仅统计NAACL, ACL, EMNLP, COLING近五年主会(长短文)及findings,代码
Author: Type-C, yanpengt06@gmail.com